
Java虚拟线程详解
虚拟线程是Java长期以来最重要的创新之一。虚拟线程是在Loom项目中开发的,从 Java 19开始作为预览功能被纳入JDK,从Java 21开始作为最终版本(JEP 444)。
在本文中,您将了解到:
- 为什么需要虚拟线程?
- 什么是虚拟线程,它们如何工作?
- 如何使用虚拟线程?
- 如何创建虚拟线程,可以启动多少个虚拟线程?
- 如何在
Spring和Jakarta EE中使用虚拟线程? - 虚拟线程有哪些优势?
- 虚拟线程不是什么,有哪些限制?
为什么需要虚拟线程?
维护过高负载情况下的后台应用程序的人都知道,线程往往是瓶颈所在。每收到一个请求,都需要一个线程来处理。一个 Java 线程对应一个操作系统线程,而这些线程都很耗费资源:
- 操作系统线程会为堆栈预留 1 MB 的空间,并根据操作系统的不同预留 32 或 64 KB 的空间。
- 启动操作系统线程大约需要 1 毫秒。
- 上下文切换在内核空间进行,对 CPU 的消耗很大。
启动次数不应超过几千次,否则会危及整个系统的稳定性。
然而,几千个请求并不总是足够的–尤其是在需要等待阻塞数据结构(如队列、锁或外部服务(如数据库、微服务或云 API))的情况下,处理一个请求需要更长的时间。
例如,如果一个请求需要 2 秒钟,而我们将线程池限制为 1,000 个线程,那么每秒最多可处理 500 个请求。然而,由于 CPU 的大部分时间都在等待外部服务的响应,即使每个 CPU 内核有多个线程,CPU 的利用率也会大打折扣。
迄今为止,我们只能通过异步编程来克服这一问题,例如,使用CompletableFuture或RxJava和Project Reactor等响应式框架。
然而,任何需要维护类似以下代码的人都知道,响应式代码比顺序式代码复杂得多,而且绝对不好玩。
public CompletionStage<Response> getProduct(String productId) {
return productService
.getProductAsync(productId)
.thenCompose(
product -> {
if (product.isEmpty()) {
return CompletableFuture.completedFuture(
Response.status(Status.NOT_FOUND).build());
}
return warehouseService
.isAvailableAsync(productId)
.thenCompose(
available ->
available
? CompletableFuture.completedFuture(0)
: supplierService.getDeliveryTimeAsync(
product.get().supplier(), productId)
)
.thenApply(
daysUntilShippable ->
Response.ok(new ProductPageResponse(product.get(),daysUntilShippable))
.build());
});
}
这种代码不仅难以阅读和维护,而且极难调试。例如,在这里设置断点毫无意义,因为代码只是定义了异步流程,但并没有执行。业务代码稍后将在单独的线程池中执行。
此外,数据库驱动程序和其他外部服务的驱动程序也必须支持异步、非阻塞模型。
什么是虚拟线程?
虚拟线程解决了这一问题,再次让我们可以编写易于阅读和维护的代码。从Java代码的角度来看,虚拟线程感觉就像普通线程,但它们并不是与操作系统线程 1:1 地映射。
取而代之的是一个所谓的载体线程池,虚拟线程被临时映射(“挂载”)到载体线程上。一旦虚拟线程遇到阻塞操作,虚拟线程就会从载体线程上移除(“卸载”),载体线程就可以执行另一个虚拟线程(新线程或之前被阻塞的线程)。
下图描述了从虚拟线程到载体线程,进而到操作系统线程的 M:N 映射:
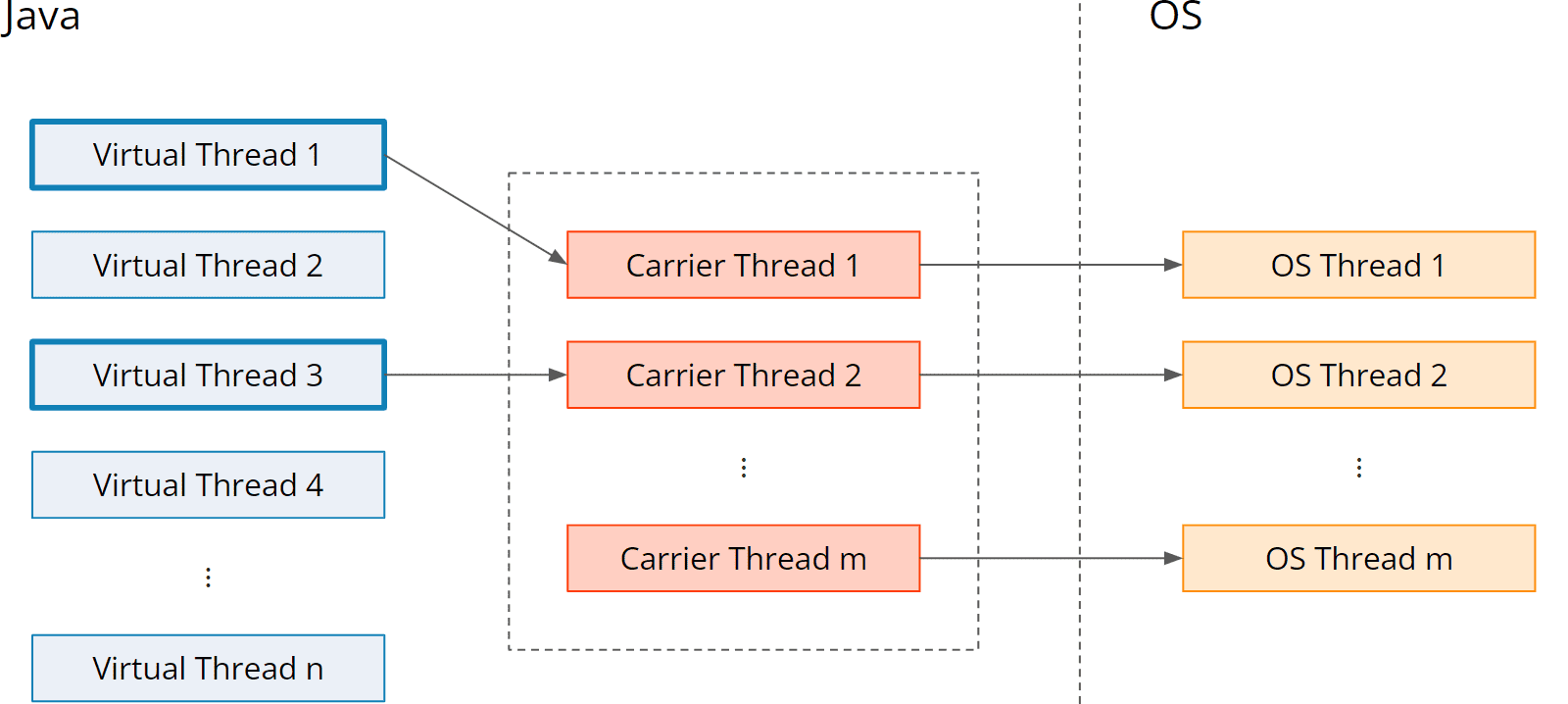
载体线程池是一个ForkJoinPool,即每个线程都有自己的队列,并在自己的队列为空时从其他线程的队列中 "偷取 "任务。其大小默认设置为 Runtime.getRuntime().availableProcessors(),并可通过虚拟机选项 jdk.virtualThreadScheduler.parallelism 进行调整。
例如,在一段时间内,三个任务的 CPU 活动(每个任务执行代码四次,中间阻塞三次,阻塞时间相对较长)可映射到一个载波线程,如下所示:
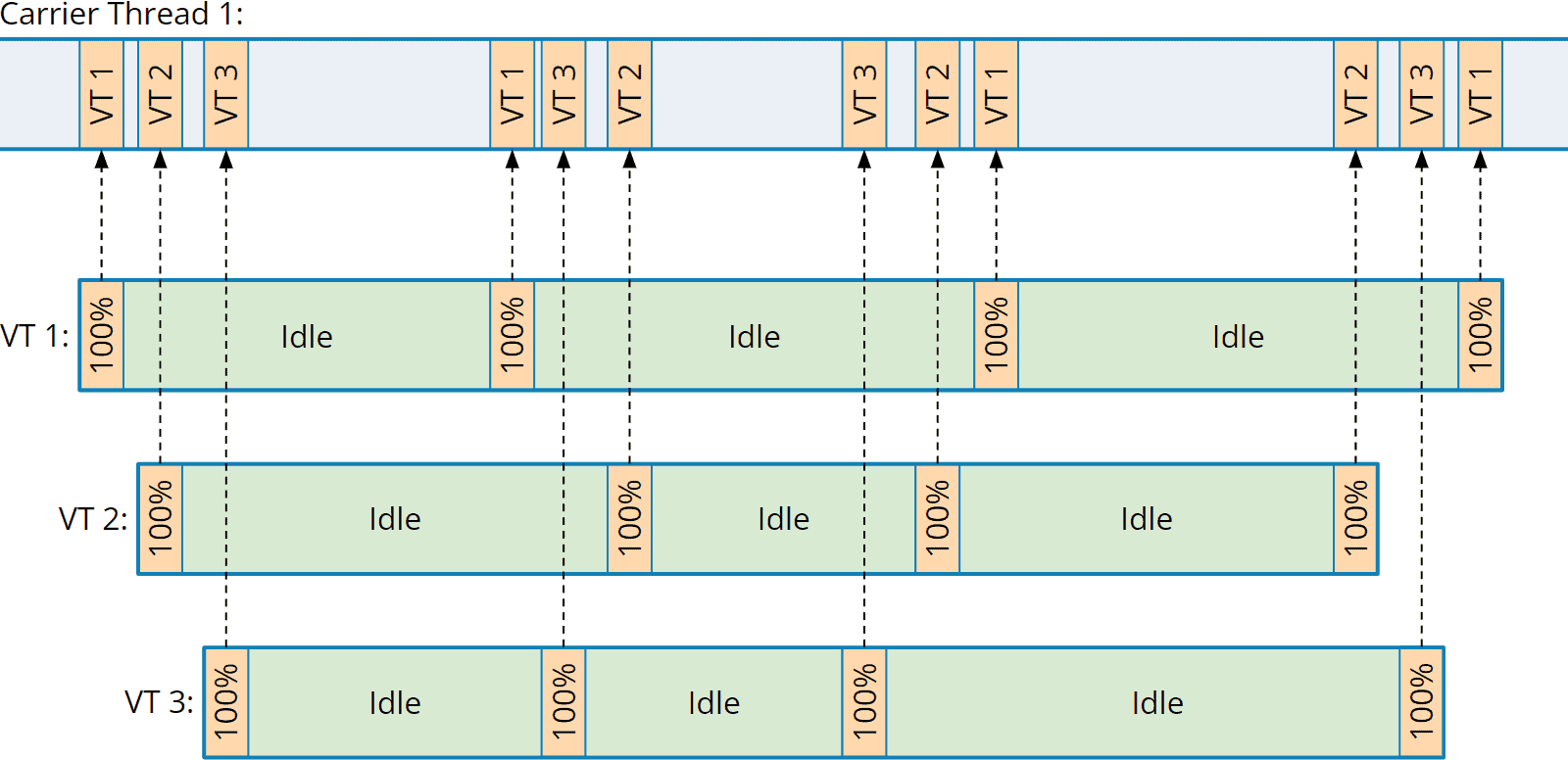
这样,阻塞操作就不会再阻塞正在执行的载波线程,我们就可以使用少量的载波线程池并发处理大量请求。
这样,我们就可以像这样简单地实现上面的示例用例:
public ProductPageResponse getProduct(String productId) {
Product product = productService.getProduct(productId).orElseThrow(NotFoundException::new);
boolean available = warehouseService.isAvailable(productId);
int shipsInDays = available ? 0 : supplierService.getDeliveryTime(product.supplier(),productId);
return new ProductPageResponse(product, shipsInDays);
}
这种代码不仅更容易编写和读取,而且与任何顺序代码一样,可以通过常规方法进行调试。
如果您的代码已经是这样的了,也就是说,您从未改用过异步编程,那么我有一个好消息:您可以继续使用您的代码,而无需改变虚拟线程。
虚拟线程 - 示例
我们还可以在没有后台框架的情况下演示虚拟线程的强大功能。为此,我们模拟了一个与上述类似的场景:我们启动了 1000 个任务,每个任务等待一秒钟(模拟访问外部 API),然后返回一个结果(示例中为随机数)。
首先,我们执行任务:
public class Task implements Callable<Integer> {
private final int number;
public Task(int number) {
this.number = number;
}
@Override
public Integer call() {
System.out.printf( "Thread %s - Task %d waiting...%n", Thread.currentThread().getName(), number);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.printf( "Thread %s - Task %d canceled.%n",Thread.currentThread().getName(),number);
return -1;
}
System.out.printf( "Thread %s - Task %d finished.%n", Thread.currentThread().getName(), number);
return ThreadLocalRandom.current().nextInt(100);
}
}
现在,我们来测量由 100 个平台线程(即非虚拟线程)组成的线程池处理全部 1000 个任务所需的时间:
try (ExecutorService executor = Executors.newFixedThreadPool(100)) {
List < Task > tasks = new ArrayList < > ();
for (int i = 0; i < 1_000; i++) {
tasks.add(new Task(i));
}
long time = System.currentTimeMillis();
List<Future<Integer>> futures = executor.invokeAll(tasks);
long sum = 0;
for (Future <Integer> future: futures) {
sum += future.get();
}
time = System.currentTimeMillis() - time;
System.out.println("sum = " + sum + "; time = " + time + " ms");
}
从 Java 19 开始,ExecutorService 可以自动关闭,也就是说,它可以被一个 try-with-resources 代码块包围。在代码块结束时,会调用 ExecutorService.close(),然后调用 shutdown() 和 awaitTermination(),如果线程在 awaitTermination() 过程中被中断,还可能调用 shutdownNow()。
程序运行了 10 多秒钟。这是意料之中的:
1000 个任务除以 100 个线程 = 每个线程 10 个任务
每个平台线程必须顺序处理 10 个任务,每个任务持续约 1 秒钟。
接下来,我们用虚拟线程测试整个过程。因此,我们只需替换语句:
Executors.newFixedThreadPool(100)
改为:
Executors.newVirtualThreadPerTaskExecutor()
该执行器不使用线程池,而是为每个任务创建一个新的虚拟线程。
之后,程序不再需要 10 秒,而只需要 1 秒多一点。由于每个任务都要等待 1 秒钟,因此速度很难更快。
令人印象深刻:即使是 10000 个任务,我们的程序也能在一秒多一点的时间内处理完毕。
只有到了 100,000 个任务时,吞吐量才会明显下降:我的笔记本电脑需要大约 4 秒钟才能完成这个任务,与线程池相比,这仍然是非常快的速度,因为线程池需要将近 17 分钟才能完成这个任务。
如何创建虚拟线程?
我们已经了解了创建虚拟线程的一种方法:我们使用Executors.newVirtualThreadPerTaskExecutor()创建的执行器服务会为每个任务创建一个新的虚拟线程。
我们还可以使用Thread.startVirtualThread()或Thread.ofVirtual().start()来显式启动虚拟线程:
Thread.startVirtualThread(() - > {
// code to run in thread
});
Thread.ofVirtual().start(() - > {
// code to run in thread
});
在第二种变量中,Thread.ofVirtual()返回一个VirtualThreadBuilder,其start()方法会启动一个虚拟线程。另一种方法Thread.ofPlatform()返回一个PlatformThreadBuilder,我们可以通过它启动一个平台线程。
这两种创建器都实现了 Thread.Builder 接口。这样,我们就能编写灵活的代码,在运行时决定是在虚拟线程还是平台线程中运行:
Thread.Builder threadBuilder = createThreadBuilder();
threadBuilder.start(() - > {
// code to run in thread
});
顺便说一句,你可以通过Thread.currentThread().isVirtual()来了解代码是否在虚拟线程中运行。
可以启动多少个虚拟线程?
在此GitHub代码库中,您可以找到几个演示程序,它们展示了虚拟线程的功能。
通过HowManyVirtualThreadsDoingSomething类,您可以测试系统上可以运行多少个虚拟线程。程序会启动越来越多的线程,并在这些线程中无限循环执行Thread.sleep()操作,以模拟等待数据库或外部 API 的响应。尝试使用VM选项 -Xmx 为程序提供尽可能多的堆内存。
在我的64GB机器上,可以顺利启动 20,000,000 个虚拟线程,如果耐心一点,甚至可以启动 30,000,000 个虚拟线程。从那时起,垃圾回收器就开始不停地执行全 GC,因为虚拟线程的堆栈被 "停放 "在堆上,即所谓的 StackChunk 对象中,一旦虚拟线程阻塞,堆栈就会被 “停放”。不久之后,应用程序就因 “OutOfMemoryError”(内存不足错误)而终止。
通过HowManyPlatformThreadsDoingSomething类,您还可以测试系统支持多少个平台线程。但请注意:大多数情况下,程序会在某一时刻以 "OutOfMemoryError "结束(对我来说,线程数在 80,000 到 90,000 之间),但也可能导致电脑崩溃。
如何在 Jakarta EE 中使用虚拟线程?
本文开头的示例方法作为Jakarta RESTful Webservices Controller(首先不使用虚拟线程)将如下所示:
@GET
@Path("/product/{productId}")
public ProductPageResponse getProduct(@PathParam("productId") String productId) {
Product product = productService.getProduct(productId)
.orElseThrow(NotFoundException::new);
boolean available = warehouseService.isAvailable(productId);
int shipsInDays =
available ? 0 : supplierService.getDeliveryTime(product.supplier(), productId);
return new ProductPageResponse(product, shipsInDays);
}
现在,要在虚拟线程上运行该控制器,我们只需添加一行注解@RunOnVirtualThread:
@GET
@Path("/product/{productId}")
@RunOnVirtualThread
public ProductPageResponse getProduct(@PathParam("productId") String productId) {
Product product = productService.getProduct(productId)
.orElseThrow(NotFoundException::new);
boolean available = warehouseService.isAvailable(productId);
int shipsInDays =
available ? 0 : supplierService.getDeliveryTime(product.supplier(), productId);
return new ProductPageResponse(product, shipsInDays);
}
我们无需更改方法主体中的任何字符。
@RunOnVirtualThread定义于Jakarta EE 11,该版本计划于 2024 年第一季度发布。
如何在Quarkus中使用虚拟线程?
Quarkus自2.10版起(即自 2022 年 6 月起)已支持 Jakarta EE 11 中定义的@RunOnVirtualThread注解。因此,使用当前版本的Quarkus,你已经可以使用上面显示的代码了。
在此GitHub 代码库中,你可以找到一个带有上图所示控制器的 Quarkus 应用程序示例,其中一个带有平台线程,一个带有虚拟线程,还有一个带有CompletableFuture的异步变体。README 解释了如何启动应用程序以及如何调用这三个控制器。
如何在Spring中使用虚拟线程?
在Spring中,控制器应该是这样的:
@GetMapping("/stage1-seq/product/{productId}")
public ProductPageResponse getProduct(@PathVariable("productId") String productId) {
Product product =
productService
.getProduct(productId)
.orElseThrow(() - > new ResponseStatusException(NOT_FOUND));
boolean available = warehouseService.isAvailable(productId);
int shipsInDays =
available ? 0 : supplierService.getDeliveryTime(product.supplier(), productId);
return new ProductPageResponse(product, shipsInDays);
}
不过,要切换到虚拟线程,您需要采取一些不同的方法。根据Spring 文档,你必须定义以下两个Bean:
@Bean(TaskExecutionAutoConfiguration.APPLICATION_TASK_EXECUTOR_BEAN_NAME)
public AsyncTaskExecutor asyncTaskExecutor() {
return new TaskExecutorAdapter(Executors.newVirtualThreadPerTaskExecutor());
}
@Bean
public TomcatProtocolHandlerCustomizer<<?> protocolHandlerVirtualThreadExecutorCustomizer() {
return protocolHandler - > {
protocolHandler.setExecutor(Executors.newVirtualThreadPerTaskExecutor());
};
}
不过,这会导致所有控制器都运行在虚拟线程上,这对于大多数使用情况来说可能没问题,但对于 CPU 处理量大的任务来说就不行了–这些任务应始终运行在平台线程上。
在此GitHub 代码库中,您可以找到一个带有上图所示控制器的示例 Spring 应用程序。README 介绍了如何启动应用程序,以及如何将控制器从平台线程切换到虚拟线程。
虚拟线程的优势
虚拟线程具有令人印象深刻的优势:
首先,成本低廉:
- 它们的创建速度比平台线程快得多:创建一个平台线程大约需要 1 毫秒,而创建一个虚拟线程不到 1 微秒。
- 它们所需的内存更少:平台线程为堆栈预留 1 MB 的内存,并根据操作系统的不同预先投入 32 至 64 KB 的内存。而虚拟线程的起始内存约为 1 KB。不过,这只适用于平面调用堆栈。一个半兆字节大小的调用堆栈在两种线程变体中都需要这半兆字节。
- 阻塞虚拟线程的成本很低,因为阻塞的虚拟线程不会阻塞操作系统线程。不过,虚拟线程并不自由,因为它的堆栈需要复制到堆中。
- 上下文切换的速度很快,因为它们是在用户空间而非内核空间执行的,而且 JVM 已经进行了大量优化,使它们的速度更快。
其次,我们可以以熟悉的方式使用虚拟线程:
- 对 Thread 和 ExecutorService API 的改动微乎其微。
- 我们不再需要编写带有回调的异步代码,而是可以按照传统的按请求阻塞线程方式编写代码。
- 我们可以使用现有工具调试、观察和剖析虚拟线程。
虚拟线程不是什么?
当然,虚拟线程并非只有优点。让我们先看看虚拟线程不是什么,以及我们不能或不应该用它们做什么:
- 虚拟线程不是速度更快的线程–它们无法在相同时间内比平台线程执行更多的 CPU 指令。
- 它们不是抢占式的:虚拟线程在执行 CPU 密集型任务时,不会从载体线程上卸载。因此,如果有 20 个载体线程和 20 个虚拟线程占用 CPU 而不阻塞,则不会执行其他虚拟线程。
- 它们提供的抽象级别并不比平台线程高。你需要注意使用普通线程时同样需要注意的所有细微问题。也就是说,如果虚拟线程访问共享数据,就必须注意可见性问题,还必须同步原子操作,等等。
虚拟线程有哪些限制?
您应该了解以下限制。其中许多限制将在未来的 Java 版本中删除:
不支持的阻塞操作
尽管 JDK 中的绝大多数阻塞操作都已重写以支持虚拟线程,但仍有一些操作不会从载体线程卸载虚拟线程:
- File I/O – 在不久的将来也将进行调整
Object.wait()
在这两种情况下,被阻塞的虚拟线程也会阻塞载波线程。为了弥补这一缺陷,这两种操作都会暂时增加载波线程的数量,最多可达 256 个线程,可通过虚拟机选项jdk.virtualThreadScheduler.maxPoolSize进行更改。
Pinning
Pinning是指,阻塞操作通常会从虚拟线程的载体线程上卸载虚拟线程,但由于虚拟线程已被"Pinning"到其载体线程上(即不允许更改载体线程),因此无法卸载。这种情况有两种:
- 同步块内
- 如果调用栈中包含对本地代码的调用
原因是在这两种情况下,都可能存在指向堆栈内存地址的指针。如果栈在卸载时被停在堆上,而在加载时又被移回栈上,那么它最终可能会出现在不同的内存地址上。这样,这些指针就会失效。
使用虚拟机选项-Djdk.tracePinnedThread=full/short可以在虚拟线程阻塞时获得完整/简短的堆栈跟踪。
您可以使用ReentrantLock替换阻塞操作周围的同步块。
线程转储中没有锁
线程转储目前不包含虚拟线程持有的锁或阻塞虚拟线程的数据。因此,它们不会显示虚拟线程之间或虚拟线程与平台线程之间的死锁。
使用虚拟线程进行线程转储
通过jcmd <pid> Thread.print打印的传统线程转储不包含虚拟线程。原因是该命令会停止虚拟机以创建运行线程的快照。这对于几百甚至几千个线程是可行的,但对于几百万个线程就不可行了。
因此,我们实施了一种新的线程转储变体,它不会停止虚拟机(因此,线程转储本身可能不一致),但会包含虚拟线程。这种新的线程转储可以用以下两种命令之一创建:
- jcmd Thread.dump_to_file -format=plain
- jcmd Thread.dump_to_file -format=json
第一条命令生成的线程转储与传统的线程转储类似,包含线程名称、ID 和堆栈跟踪。第二条命令会生成一个 JSON 格式的文件,其中还包含线程容器、父容器和所有者线程的信息。
何时使用虚拟线程?
如果有许多任务需要并发处理,其中主要包含阻塞操作,则应使用虚拟线程。
大多数服务器应用程序都是如此。不过,如果服务器应用程序要处理 CPU 密集型任务,则应使用平台线程。
还有哪些重要因素需要考虑?
以下是使用和迁移到虚拟线程的一些提示:
- 虚拟线程是一种新技术,与异步或反应式框架相比,我们还没有太多使用虚拟线程的经验。因此,在将应用程序部署到生产环境之前,您应该对使用虚拟线程的应用程序进行密集测试。
- 尽管许多关于虚拟线程的文章会让我们相信:虚拟线程使用的内存并不比平台线程少。只有当调用堆栈较浅时,情况才会如此。如果调用堆栈较深,两种线程消耗的内存量是相同的。因此,同样的道理也适用于此:密集测试!
- 虚拟线程不需要池化。池用于共享昂贵的资源。而虚拟线程则非常便宜,最好在需要时创建一个,不再需要时就让它终止。
- 如果需要限制对资源的访问,比如多少个线程可以同时访问数据库或 API,可以使用信号而不是线程池。
- 大部分虚拟线程代码都是用 Java 编写的。因此,您必须在运行性能测试前对 JVM 进行预热,以便在测量开始前编译和优化所有字节码。
总结
虚拟线程实现了它们的承诺:它们允许我们编写可读、可维护的顺序代码,在等待锁、阻塞数据结构或文件系统或外部服务的响应时,不会阻塞操作系统线程。
虚拟线程的创建数量可达数百万。
Spring和Quarkus等常见的后端框架已经可以处理虚拟线程。不过,在切换到虚拟线程时,应密集测试应用程序。例如,确保不在虚拟线程上执行 CPU 密集型计算任务,确保框架不对虚拟线程进行池化,确保虚拟线程中不存储ThreadLocals(另请参阅 “作用域值”)。
希望你和我一样兴奋,迫不及待地想在自己的项目中使用虚拟线程!
如果您还有问题,请通过评论功能提问。