Kubernetes网络之Pods
这篇文章将试图揭开在kubernetes集群中运行的几层网络的神秘面纱。Kubernetes是一个功能强大的平台,体现了许多智能设计选择,但讨论事物交互的方式可能会让人感到困惑:pod networks, service networks, cluster IPs, container ports, host ports, node ports…我看到几只眼睛茫然。我们大多在工作中讨论这些事情,一次切换所有层次因为某些事情被破坏而有人想要修复它。如果你一次拿一块并清楚地知道每一层是如何工作的,那么所有这些都是以一种相当优雅的方式。
为了使事情集中,我将把文章分成三部分。第一部分将介绍container和pods。在第二部会研究service,这是允许pod是短暂的抽象层。最后一篇文章将介绍ingress并从群集外部获取访问pods。本文不打算成为container,kubernetes或pods的基本介绍。要了解更多关于容器的工作可以看这个概述。kubernetes的高级概述可以在这里找到,并且这里特别概述了pods。最后,对网络和IP地址空间的基本熟悉将是有帮助的。

Pods
什么是Pod? 一个pod由一个或多个容器组成,并配置为共享网络堆栈和其他资源,如volume。Pod是kubernetes应用程序的基本单元。”共享网络堆栈”实际上意味着什么?实际上,它意味着pod中的所有容器都可以在localhost上相互访问。如果我有一个运行nginx的容器并侦听端口80和另一个运行scrapyd的容器,那么第二个容器可以连接到第一个容器http://localhost。但这是如何运作的呢?让我们看一下当我们在本地机器上启动docker容器时的典型情况:
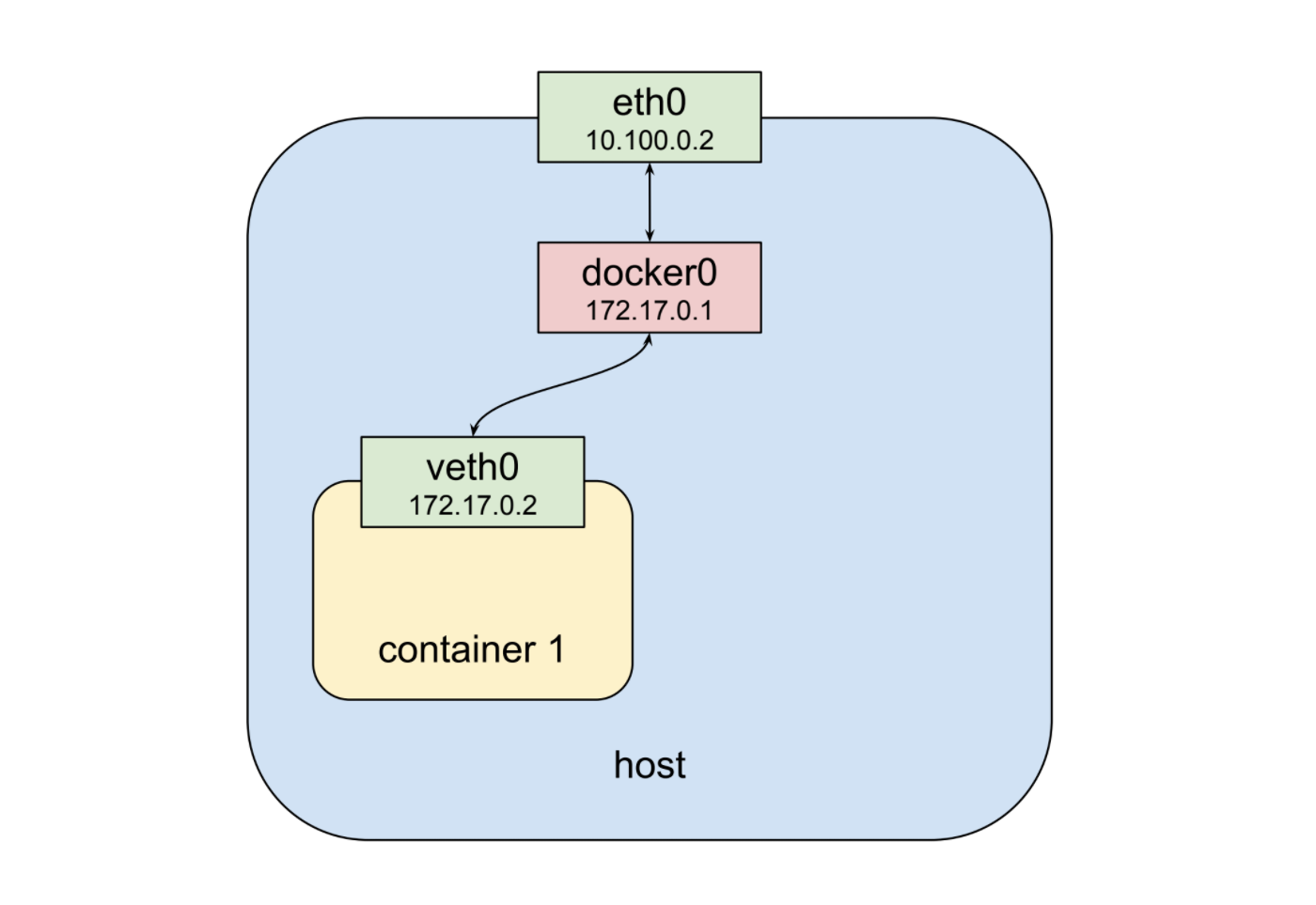
从上到下,我们有一个物理网络接口eth0。附加到它的是一个桥接器docker0,并附加到它是一个虚拟网络接口veth0。请注意,docker0和veth0都在同一网络上,本例中为172.17.0.0/24。在此网络上,docker0被分配为172.17.0.1,并且是veth0的默认网关,分配为172.17.0.2。由于在启动容器时如何配置网络命名空间,其中的进程只能看到veth0,并通过docker0和eth0与外界通信。现在让我们启动第二个容器:
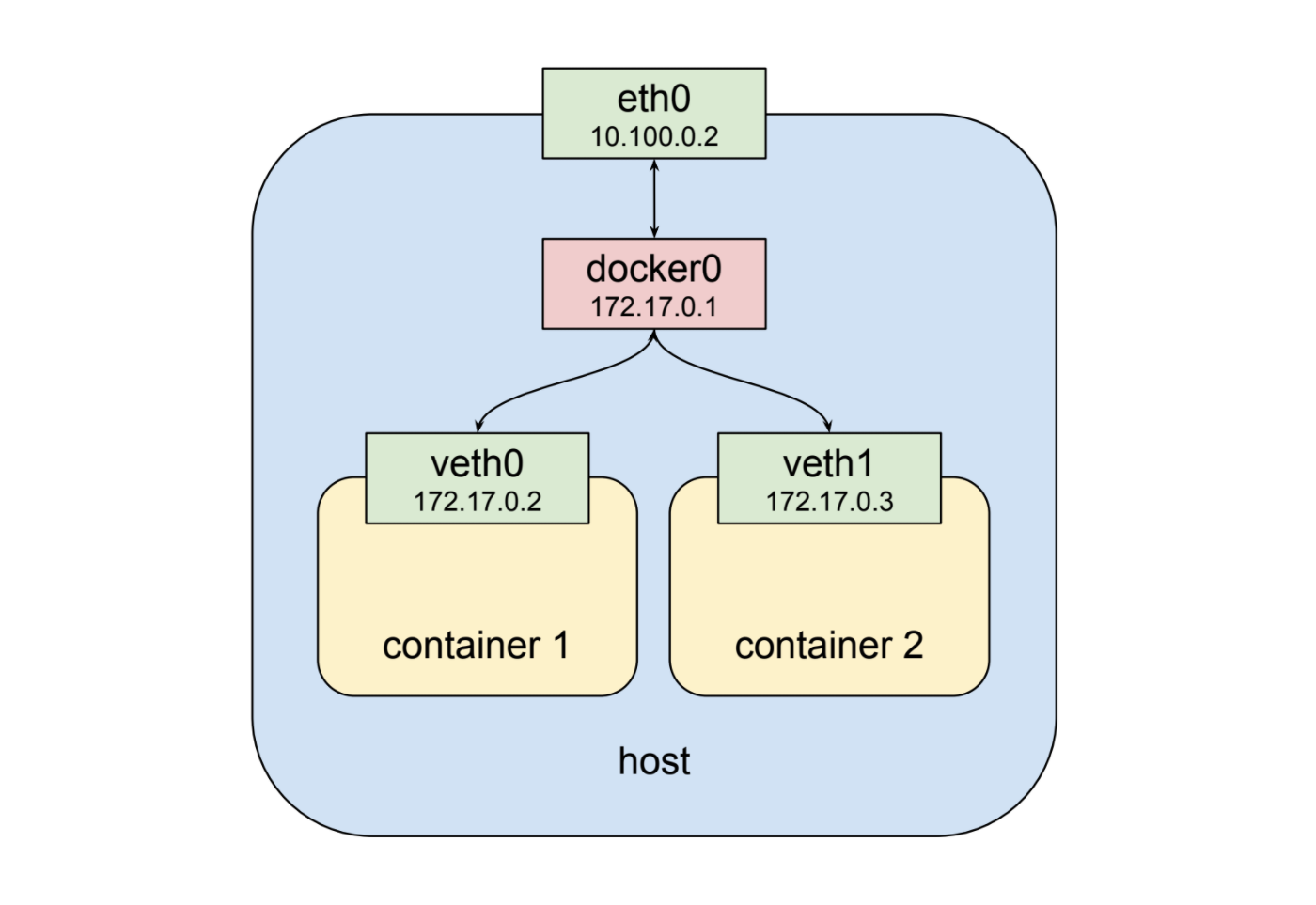
如上所示,第二个容器获得一个新的虚拟网络接口veth1,连接到同一个docker0网桥。*此接口被分配172.17.0.3,因此它与网桥和第一个容器位于同一逻辑网络上,并且两个容器都可以只要他们能以某种方式发现其他容器的IP地址,就可以通过网桥进行通信。
这很好,除了它不会让我们进入kubernetes pod的”共享网络堆栈”。幸运的是,名称空间非常灵活。 Docker可以启动容器,而不是为它创建新的虚拟网络接口,指定它共享现有接口。在这种情况下,上面的图表看起来有点不同:
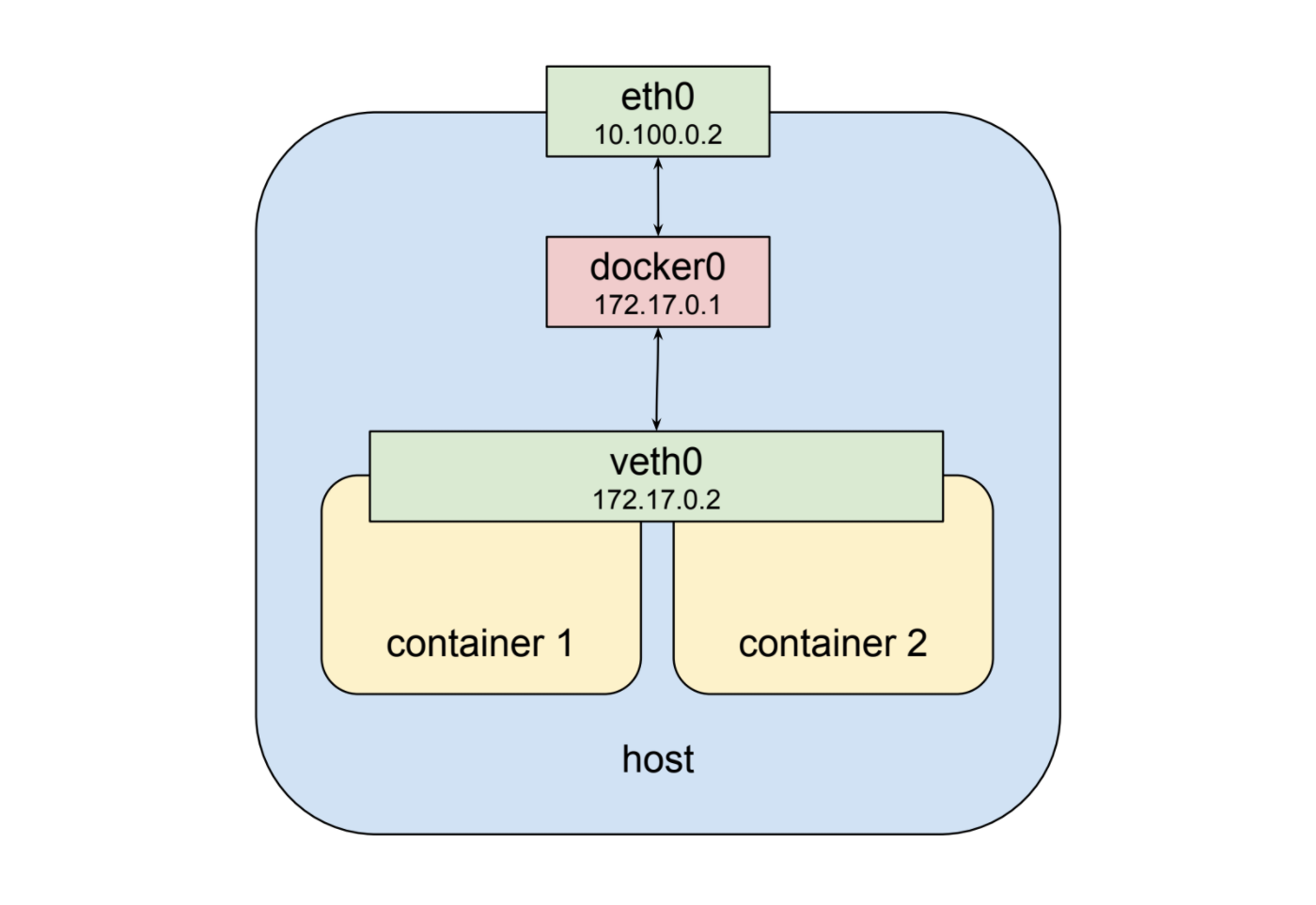
现在第二个容器看到veth0而不是像前面的例子那样得到自己的veth1。这有一些影响:首先,两个容器都可以在172.17.0.2上从外部寻址,并且在内部每个容器都可以在localhost上命中另一个容器打开的端口。这也意味着两个容器无法打开同一个端口,这是一个限制,但与在单个主机上运行多个进程时的情况没有什么不同。通过这种方式,一组进程可以充分利用容器的分离和隔离,同时在最简单的网络环境中协作。
Kubernetes通过为每个pod创建一个特殊容器来实现此模式,其唯一目的是为其他容器提供网络接口。如果你进入一个kubernetes集群节点,该节点上安排了pod并运行docker ps,你将看到至少一个使用pause命令启动的容器。 pause命令暂停当前进程,直到收到一个信号,因此这些容器除睡眠外什么都不做,直到kubernetes向它们发送SIGTERM。尽管缺乏活动,”暂停”容器是容器的核心,提供了所有其他容器将用于彼此和外部世界通信的虚拟网络接口。因此,在一个假设的类似pod的东西中,最后一张图片看起来像这样:
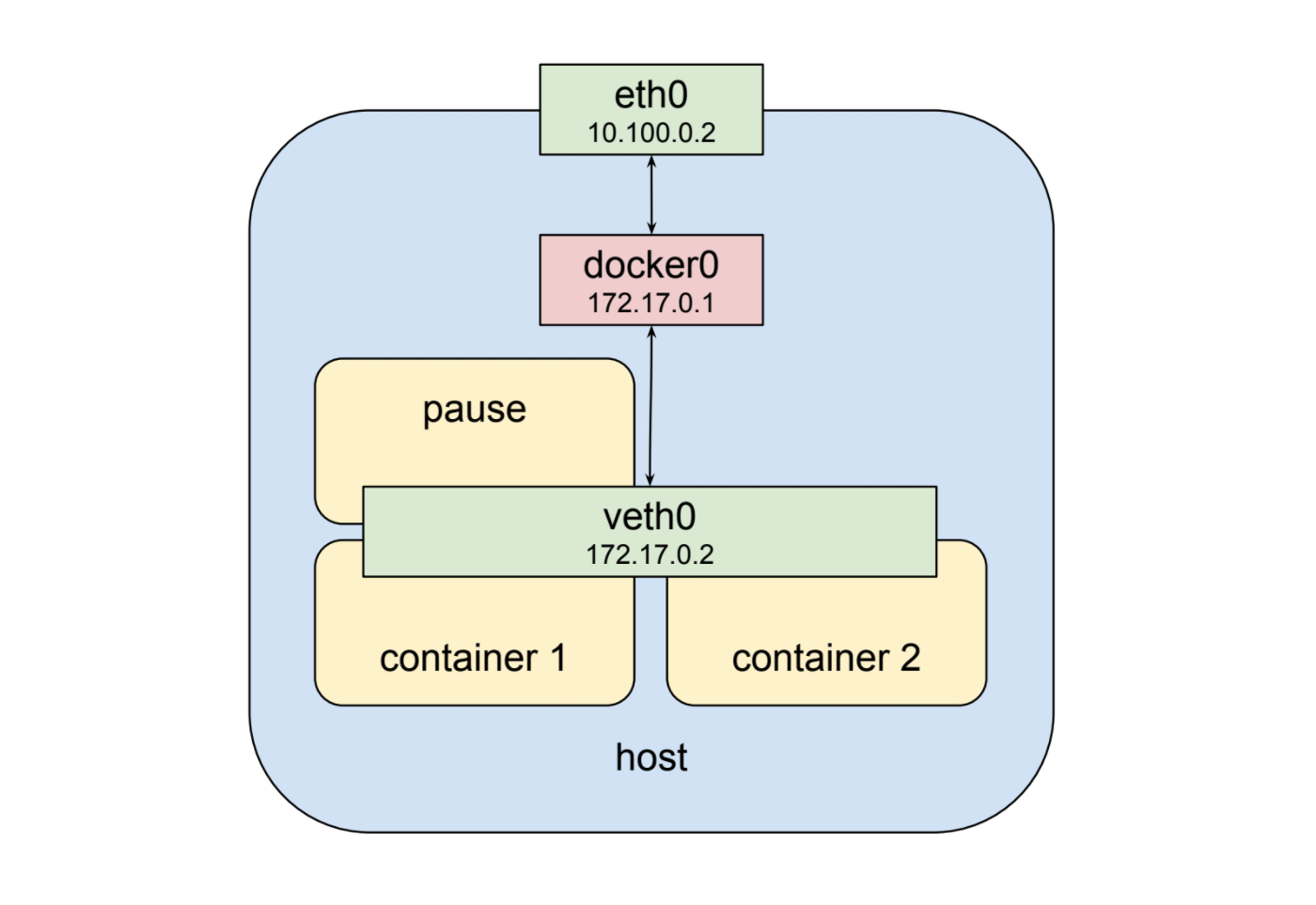
Pod网络
这一切都非常酷,但是一个装满容器的容器可以互相通信并不能让我们成为一个系统。由于在我讨论服务的下一篇文章中会更清楚的原因,kubernetes设计的核心要求pod能够与其他pod通信,无论它们是在同一本地主机上运行还是在单独的主机上运行。要了解这是如何发生的,我们需要升级一个级别并查看集群中的节点。本节将包含对网络路由和路由的一些不幸的引用,这是我认识到的所有人类都希望避免的主题。找到一个关于IP路由的简明扼要的教程是很困难的,但如果你想要一个体面的评论维基百科关于这个主题的文章并不可怕。
kubernetes集群由一个或多个节点组成。节点是一个主机系统,无论是物理机还是虚拟机,具有容器运行时及其依赖关系(主要是docker)和几个kubernetes系统组件,它们连接到允许它到达集群中其他节点的网络。两个节点的简单集群可能如下所示:
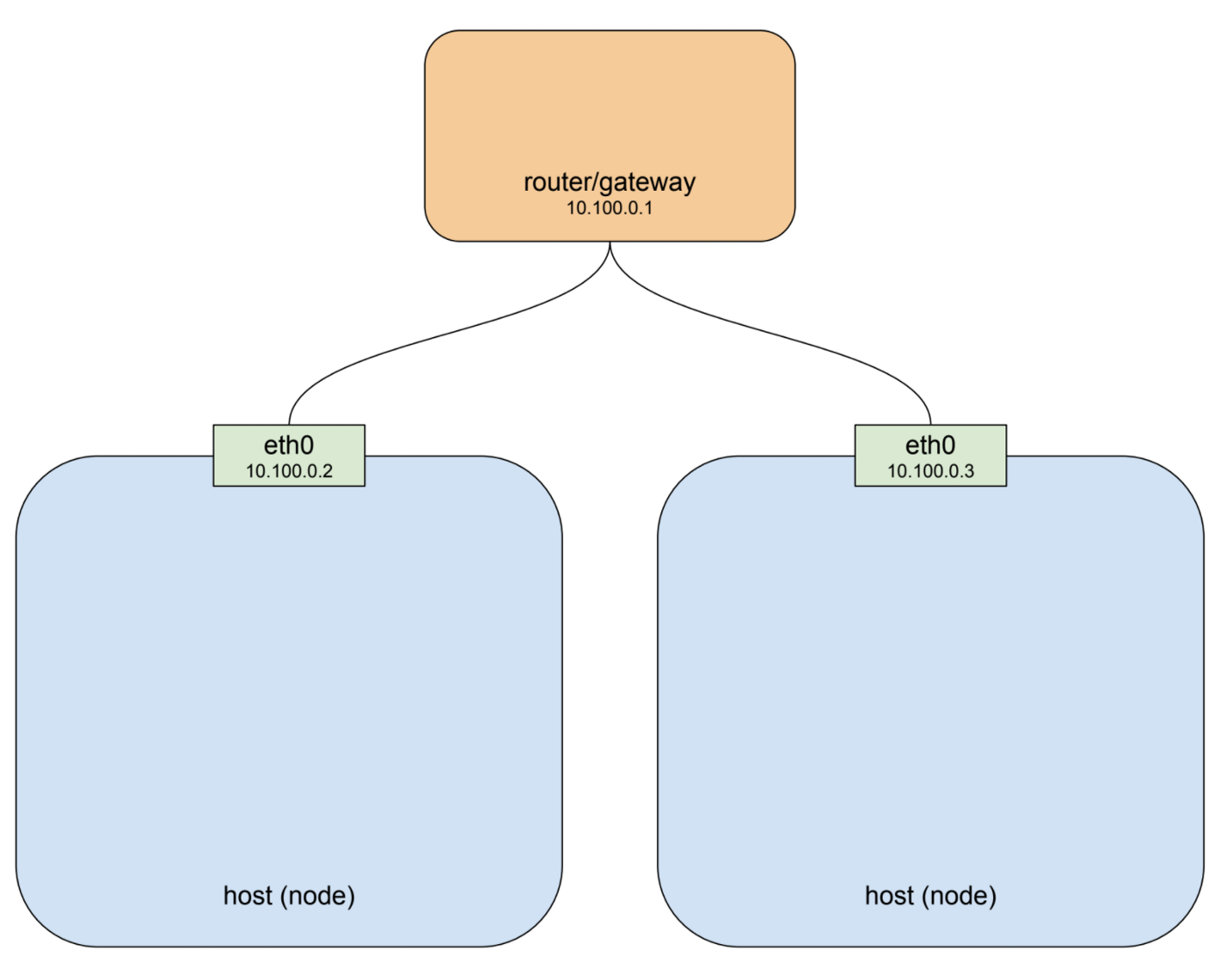
如果您在GCP或AWS等云平台上运行群集,那么绘制得非常接近单个项目环境的默认网络架构。出于说明的目的,我在本例中使用了专用网络10.100.0.0/24,因此路由器为10.100.0.1,两个实例分别为10.100.0.2和10.100.0.3。鉴于此设置,每个实例都可以在eth0上与另一个实例进行通信。这很好,但回想一下,我们上面看到的那个pod不在这个私人网络上:它完全挂在不同网络上的一座桥上,一块是虚拟的,只存在于一个特定的节点上。为了使这个更清楚,让我们将类似pod的东西放回到图片中:
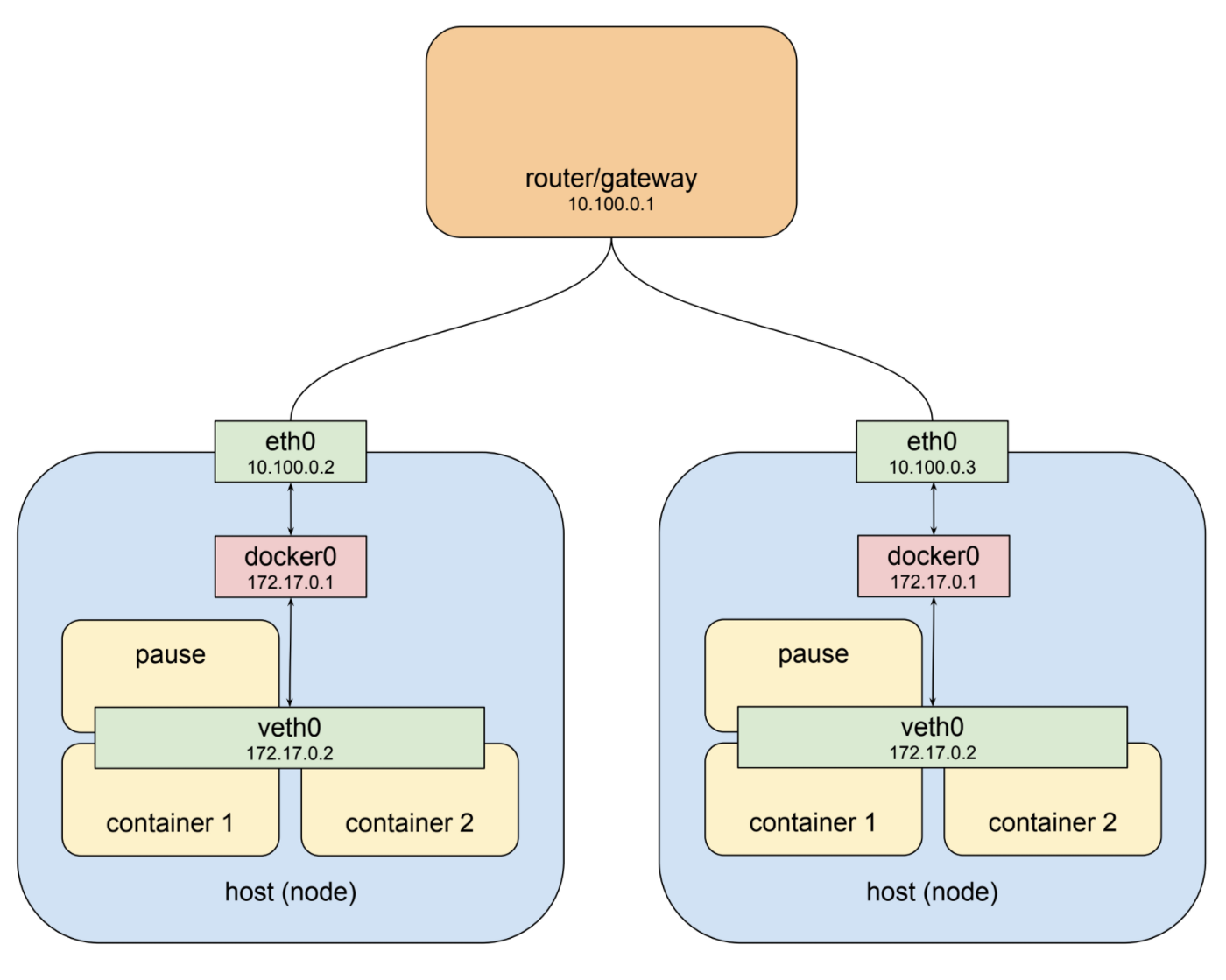
左侧主机的接口eth0的地址为10.100.0.2,默认网关为10.100.0.1的路由器。连接到该接口的是桥接器docker0,地址为172.17.0.1,并连接到接口veth0,地址为172.17.0.2。 veth0接口是使用pause容器创建的,并且凭借共享网络堆栈在所有三个容器中可见。由于在创建网桥时设置了本地路由规则,任何到达eth0且目的地址为172.17.0.2的数据包都将被转发到网桥,网桥会将其发送到veth0。听起来不错。如果我们知道我们在这台主机上有一个172.17.0.2的pod,我们可以为我们的路由器添加规则,将该地址的下一跳设置为10.100.0.2,它们将从那里转发到veth0。现在让我们看看其他主机。
右侧的主机也有eth0,地址为10.100.0.3,在10.100.0.1使用相同的默认网关,并再次连接到docker0网桥,地址为172.17.0.1。嗯。那将是一个问题。现在这个地址可能实际上与主机1上的另一个桥不一样了。我在这里做了同样的事情,因为那是一个病态的最坏情况,如果你刚刚安装了docker并且让它做了,它可能会很好用它的东西。但即使选择的网络不同,这突出了更基本的问题,即一个节点通常不知道在另一个节点上为哪个专用地址空间分配了什么,我们需要知道如果我们要发送数据包它,让他们到达正确的地方。显然,需要一些结构。
Kubernetes以两种方式提供这种结构。首先,它为每个节点上的网桥分配一个总地址空间,然后根据构建网桥的节点分配该空间内的网桥地址。其次,它将路由规则添加到10.100.0.1的网关,告诉它应该如何路由发往每个网桥的数据包,即哪个节点可以通过该网桥到达。虚拟网络接口,网桥和路由规则的这种组合通常称为覆盖网络。在谈论kubernetes时,我通常称这个网络为“pod网络”,因为它是一个覆盖网络,允许pod在任何节点上来回通信。以下是kubernetes的上图:
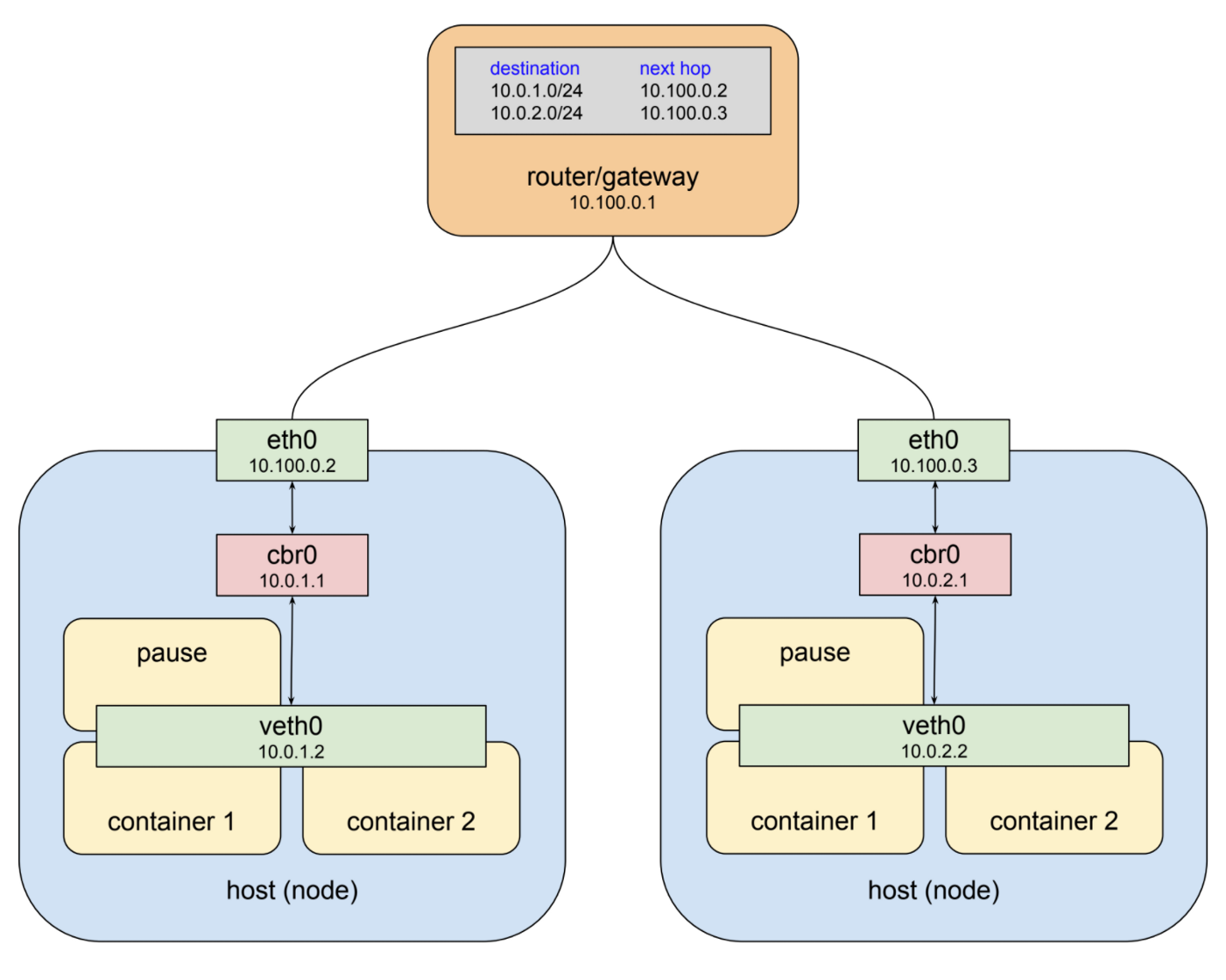
应该跳出来的一件事是我已经将桥接器的名称从“docker0”更改为“cbr0”.Kubernetes不使用标准的docker bridge设备,事实上“cbr”是“自定义桥接器”的缩写。不知道所有关于它的定制,但它是在kubernetes上运行的docker与默认安装之间的重要区别之一。另一件需要注意的是,本例中分配给网桥的地址空间为10.0.0.0/14。这是从我们在Google Cloud中的一个分段群集中获取的,因此是一个真实的例子。可能会为您的群集分配完全不同的范围。不幸的是,目前没有办法使用kubectl实用程序公开它,但是在GCP上,您可以运行gcloud container clusters describe <cluster>命令并查找clusterIpv4Cidr属性。
通常,您不需要考虑此网络的功能。当一个pod与另一个pod通话时,它通常通过服务的抽象来实现,这是一种软件定义的代理,将成为本系列下一篇文章的主题。但是pod网络地址会弹出日志和调试时,在某些情况下,您可能需要显式路由此网络。例如,离开绑定到10.0.0.0/8范围内的任何地址的kubernetes pod的流量默认情况下不是NAT’d,因此如果您与该范围内的另一个专用网络上的服务进行通信,则可能需要设置规则来路由数据包回到pods。希望本文将帮助您采取正确的步骤,使这些方案正常工作。
翻译: https://medium.com/google-cloud/understanding-kubernetes-networking-pods-7117dd28727